T-SQL 语句编写的一些简单方针
- 编写语句前,一定要了解业务需求。
- 确定过滤字段能否使用索引,是否合理。重复率是一个指标,可以通过查询统计信息获得。
- 不要对有索引的字段使用任何计算,包括函数。
- 小表操作优先,用小表驱动大表。执行计划里尽量是 NESTED LOOP。
- 只返回必要的字段。
- 保持 SQL 语句简单。
- 只简单的存在 2~4 个表的关联。
- 不要有复杂的过滤条件,只有 2~3 个条件判断。
- 越复杂的语句在业务量大的系统中,越会有“变异”的可能性。适度考虑用固定执行计划
- 如果要 order by 的话,尽量使用有索引的字段进行。
- 不要遗漏 join 关键字,不然的话容易发生笛卡尔积。
SELECT 语句
- 只查询需要的字段。
- 限定查询的结果集的大小。
- 高效的使用和建立索引来提高性能。
ORDER BY/DISTINCT/GROUP BY
从索引的角度分析
|
|
默认情况下的执行计划和 I/O 情况如下所示:
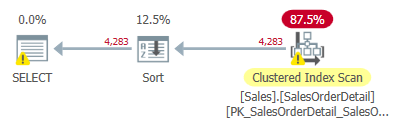

现在我们新建如下索引
|
|
从对于 Index 的分析中,我们可以看到 SQL Server 仍然选择了不使用任何 Index。

但是当我们同时在 Index 里面包含了 ProductID 和 OrderQty 的时候,SQL Server 就会选择使用我们的 Index 了。
|
|
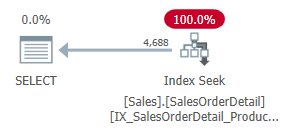
此时,从 Index 的分析中,我们可以看到如下结果:

从内存的角度分析
在进行 ORDER BY 的操作时,如果工作区内存[1]不足,就需要使用 TempDB 来完成数据的排序,从而导致了磁盘 I/O 的操作。当并发量达到一定的量级时,也会对排序操作本身产生影响。再者,TempDB 是公共资源,大批量的写入会导致磁盘资源阻塞,影响其他语句的执行。如果有必要的话,也可以把需要 ORDER BY 的字段放入 Index 中,从而避免了排序。 GROUP BY 和 DISTINCT 需要进行哈希或者排序计算。所以和 ORDER BY 一样,当工作区的内存不足时,会将一部分数据存放到 TempDB 中。所以,如果有必要,也可以在 GROUP BY 的字段上面建立 Index 以避免哈希计算。总之,在进行上述操作之前,记得评估数据量的大小。
UPDATE 语句
在默认的事务级别下,UPDATE 语句会先对数据添加更新锁,当确定需要更新的数据时,再讲更新锁转化为排它锁,然后才更新。因为更新锁和排它锁的加入,更容易并发阻塞,比如影响 SELECT 的操作。所以一般建议小量的更新使用主键或者唯一键字段来过滤需要更新的数据。
DELETE 语句
和 UPDATE 语句类似,但是因为删除数据会影响索引,所以在频繁删除数据的表中建立索引时,应该权衡数据查询和更新的比例。
WHERE 子语句
语句优化通常都是针对具有筛选条件的语句来评价的,如果没有,那么扫描表或者索引是仅剩的可选方式。一个高效的查询语句,通常都会以 Seek 去检索某个活若干个覆盖索引来查找数据。
编写 SQL 语句的一些流程。
- 明白做什么,应该从什么表中取出什么样的数据。
- 明白怎么做,用哪些字段过滤,哪些字段需要加索引。
- 字段上是否有计算函数。
- 返回的结果集是否过大。
- 是否仅查询出需要的字段。
- 确定查出来的数据是否正确。
JOIN 语句
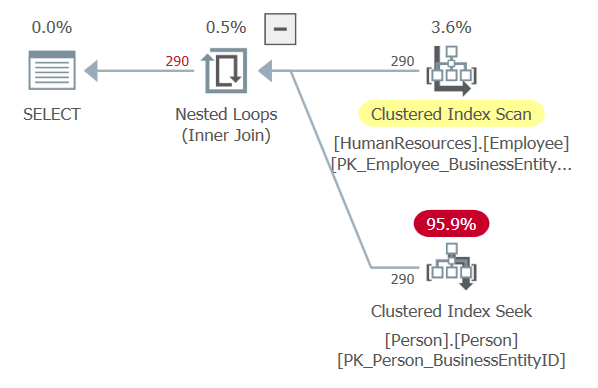
NESTED LOOP
小数据集驱动大数据集,同时如果能有合适的索引,那么 NESTED LOOP 的性能是最佳的。一般情况下, NESTED LOOP 的 I/O 操作是小表的 Scan + 大表的 Seek 或者都是索引的 Seek 操作。
MERGE JOIN
一般出现在连接的数据集的数据量相当,并且连接条件均为顺序排列的情况下。如果涉及的数据集不是已经排序的结果,那么将会多一部分排序的操作或者转为 HASH JOIN 的方式。在连接操作方式上,也分为一对多和多对多,当关联的某一方的字段上存在唯一索引时,将优先选择一对多的操作,效率比多对多更高,这点其实很好理解。

HASH JOIN
主要应用在大数据量的连接中,通过 Scan 操作将数据取出,同时对需要关联的字段进行 Hash 计算,从而得出两个集合的 hash 数据集并进行比较,然后输出。一般情况下, HASH JOIN 的操作为 Scan 操作。大数据量的情况下,效率比较低。

子查询语句
在写子查询的时候要时刻想着,语句的人为可读性如何?能很好的生成执行计划吗?一般来说,一个语句中,子查询的数量不超过3个,整个查询语句涉及的表不超过5个。一般来说,子查询会转化为常用的连接操作,如果不能转换的话,则子查询的语句会优先被执行从而作为下一个操作的输入。
- 避免在子查询中对大数据集进行汇总或排序。
- 尽量缩小子查询的返回结果集。
- 尽量使用确定性的判断符,如: =、IN、EXISTS 等,而不要使用 ANY、SOME 或者 ALL。
|
|
|
|
运行时动态管理视图
通过以下视图可以知道当前 SQL Server 的运行情况。

- 本文中,执行计划的截图均来自软件 SentryOne Plan Explorer
- Sql_handle 是以运行语句来计算 hash 值的,Plan_handle 是以该语句的执行计划来进行 hash 计算。通过这两个标识可以找到对应的语句和执行计划。