下面是一些平时经常会遗忘的正则表达式的知识点:
.只能匹配除换行符以外的任何单个字符。
-
在相关书籍中,专业名词普通字符的意思就是纯文本,而元字符代表的含义是特殊字符。
-
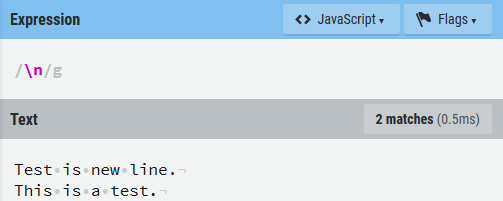
当你使用
[A-z]去匹配所有的字符时,要记得这两个字符的 ASCII 码中还有[和]等。
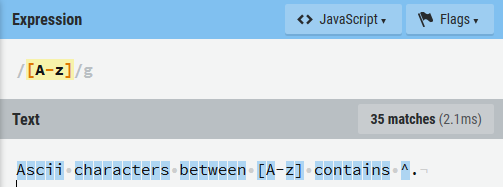
- 字符
-只是一个普通的字符。
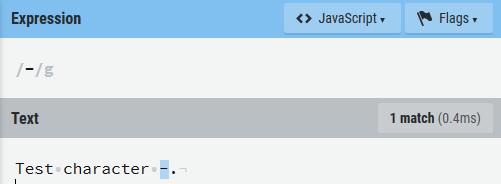
[ ]中的^用来反义之后所有在当前括号里的数字。
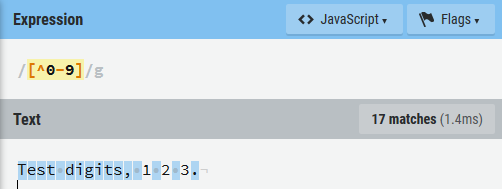
\b:回退符,\f:换页符,\n:换行符,\r:回车符,\t:制表符,\v:垂直制表符。
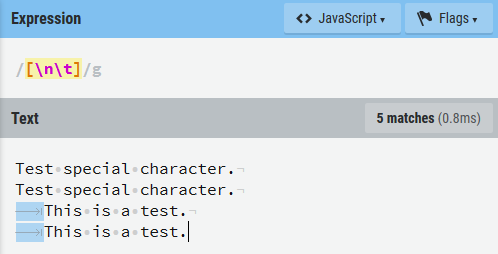
-
\r\n用于 Windows 系统中的文本行的结束标签,\n用于 Unix 类系统。 -
\d用于匹配数字,\w用于匹配字母或数字或下划线,\s用于匹配任意空白字符的含义。注意:当字母d、w、s是大写时,表示取反。
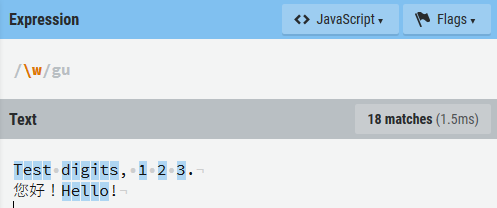
-
POSIX 字符的含义如
[:alpha:]等,很多实现不支持,比如:JavaScript。 -
当在字符集合里使用的时候,像
.、+等元字符不需要转义,但是转了也没错。

- 默认情况下,
+、*、?、{、}等元字符会使用贪婪法则去匹配尽可能多的字符,在这些符号后面增加?可以启用这些匹配模式的懒惰型版本来防止过度匹配。
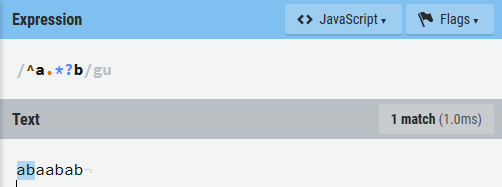
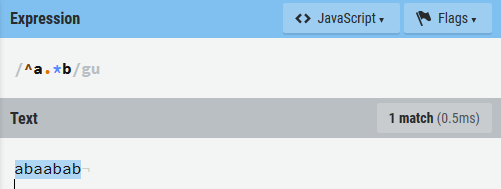
\b:单词边界匹配,\B:不匹配一个单词边界,\<:匹配单词的开头。
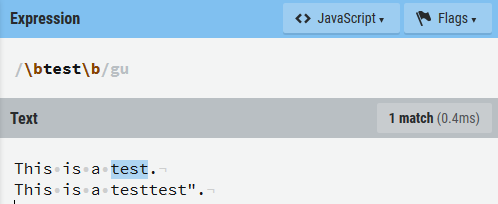
(?m)可以用于多行匹配,多用于已经指定了^或$的正则表达式。在 JavaScript 中,使用标签m来指定这一模式。除此以外,还有正向前(?=)和负向前(?!)等匹配方式。

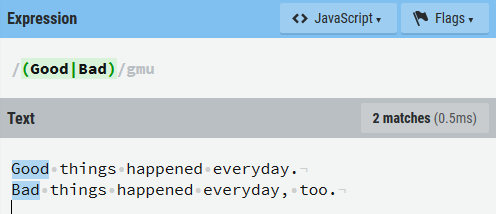
- 符号
|用于表示或(所有的左边和所有的右边取或)。
- 在有些实现的回溯引用中,
\0代表整个正则表达式。在 JavaScript 中,当执行替换时,如果使用到回溯引用,在替换语句中需要使用$代替\。
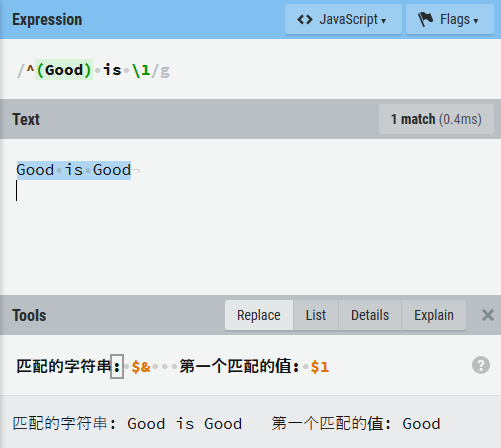
注意回溯引用是和前面的实际匹配完全相同。例子:如果第一次匹配到2个空字符,那么以后所有的相同引用都只认2个空字符!!。
-
有一些元字符用于替换的表达式中,如:
\U$1\E、$1\U$2\L等。 -
任何一个子表达式都可以转换为一个向前查找表达式,只要加上
?=前缀即可,同一个搜索模式里可以使用多个向前查找。向后查找操作符为?<=。很多正则表达式的实现均不支持。
注意:这里的向前和向后的具体含义,因为匹配文本相对于模式的方向与文本阅读方向正相反。向前/向后操作符必须放在一个子表达式里。向前查找模式的长度是可变的,可以包含
.和+之类的,但是向后查找模式只能是固定长度。
- 在线测试正则表达式的网站: https://regexr.com/
- 编写正则表达式真正困难的地方在于把不需要匹配的情况也考虑周全并确保它们都被排除!
- https://medium.com/@jitbit/cool-regex-performance-hacks-i-bumped-into-83c9fdd1976b